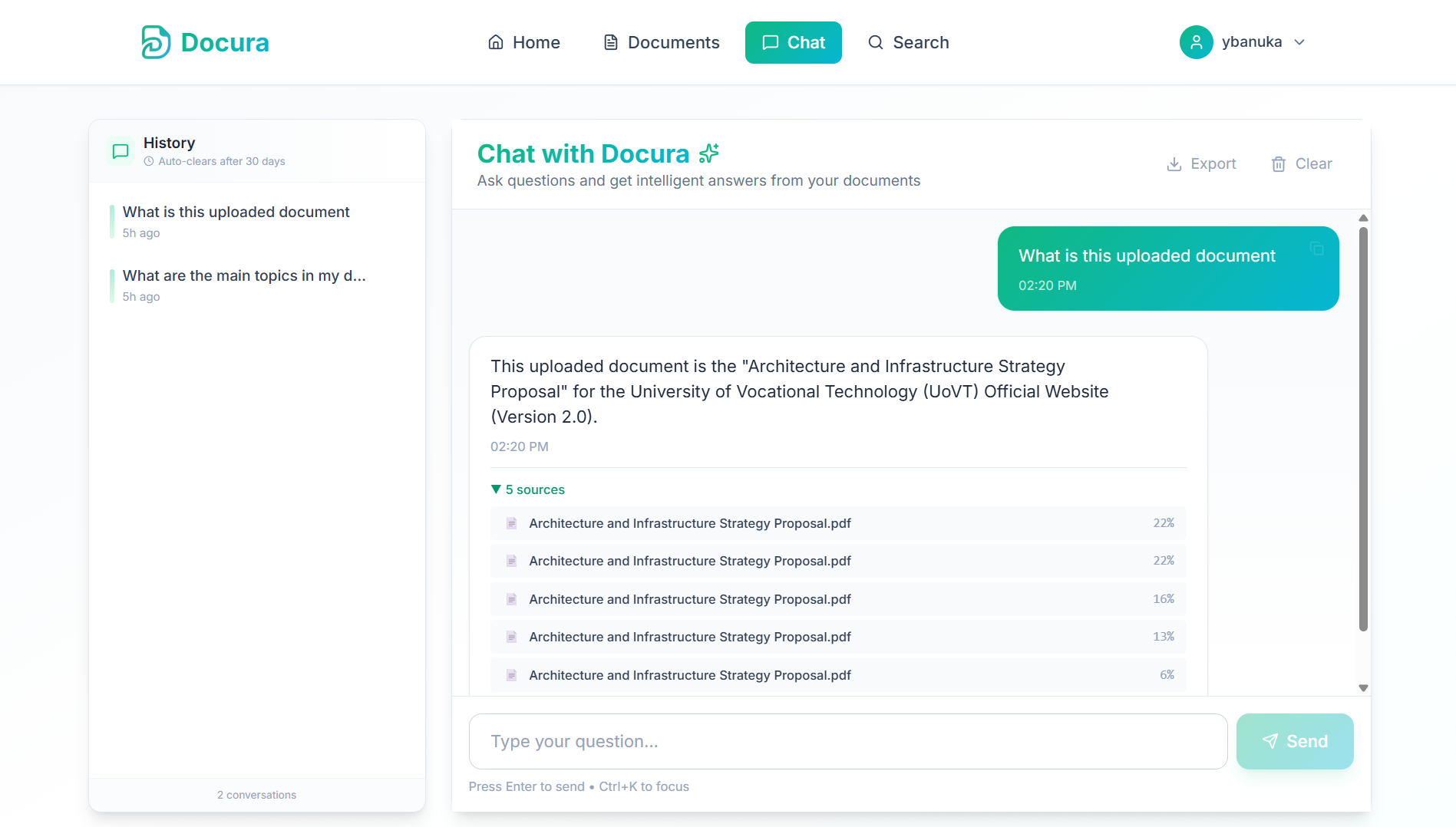
Docura
A self-hosted, production-grade document intelligence platform, where enterprise teams query proprietary documents via a LLaMA-powered AI chat without a single byte of data leaving the network perimeter.
Role
Fullstack & Infrastructure Engineer
Live Platform
docura.iamyasasbanuka.me
Timeline
Personal Project · 2026
Tech Stack
Overview
Enterprise teams increasingly handle sensitive proprietary documents, contracts, research, financial records, that cannot be sent to third-party AI APIs without violating data privacy. Existing RAG solutions either require cloud data egress or sacrifice multi-tenant isolation.
Docura solves both. It is a fully self-hosted document intelligence platform where users upload PDFs, DOCX, and TXT files and interact with them via a context-aware AI chat interface. All vector embedding runs locally inside the JVM using an ONNX runtime, data never leaves the network perimeter.
My Role
I designed and built Docura as a solo full-stack and infrastructure project, owning every layer of the system: the React + TypeScript frontend, the Spring Boot 3 / Java 21 API, the PostgreSQL vector schema, the Docker Compose orchestration on AWS EC2, the Nginx reverse proxy configuration, and the complete Prometheus + Grafana observability stack. Every architectural decision, including the choice of embedding model, database, and security model, was researched, made, and implemented independently.
The Dual AI Provider Strategy
The most critical architectural challenge was balancing privacy, cost, and generation quality simultaneously. Sending document chunks to OpenAI's embedding API would expose private data and incur per-token cost, unacceptable for a privacy-first platform. Instead, I embedded a local ONNX runtime (all-MiniLM-L6-v2, 384-dim) directly into the Spring Boot JVM. This eliminates all data egress and API costs for the most privacy-sensitive operation. For text generation, where quality matters more than strict data locality, I integrated Groq's LLaMA 3.3 70B API via Spring AI, achieving near-instant inference speeds on a hardware-constrained t3.small instance that could never run a 70B model locally. The system uses Spring AI's provider abstractions, making the AI backends fully swappable across profiles without changing application logic.
Document ETL & Chunking Pipeline
The ingestion pipeline handles PDF (Apache PDFBox), DOCX (Apache POI), and TXT files within a single @Transactional boundary, guaranteeing atomicity so a failed embedding step never leaves orphaned document records. Text is split using a custom sliding-window algorithm: 2,000-character chunks with a 200-character overlap and sentence-boundary detection. The overlap is non-negotiable, without it, a key phrase spanning a chunk boundary would be split across two chunks, significantly degrading retrieval accuracy. At query time, the top 7 most semantically similar chunks are retrieved via pgvector's cosine distance operator, providing approximately 3,000–4,000 tokens of context, enough for a grounded answer without overflowing the model's context window.
Multi-Tenant Data Isolation
Data privacy between users is enforced at three completely independent architectural layers. At the SQL layer, every vector search query includes a hard WHERE d.user_id = ? clause injected from the JWT principal, no application-level bypass can circumvent this. At the service layer, all data access methods use findByIdAndUserId(id, userId), throwing immediately if ownership mismatches. At the security layer, Spring Security's @AuthenticationPrincipal injects the authenticated user directly into every controller method. The design principle: no single-layer compromise can expose another tenant's data. This is defense-in-depth applied to a multi-tenant AI system.
Authentication & Rate Limiting
The security filter chain executes in a strict, order-dependent sequence: CorsFilter → JwtAuthenticationFilter → RateLimitFilter → RAGRateLimitFilter → AuthorizationFilter. JWT tokens use HS256 with a 24-hour access window and 7-day refresh window. Passwords are hashed with BCrypt (cost factor 10). Rate limiting uses Bucket4j with three independently enforced tiers: 100 requests/min for authenticated users (keyed by user ID), 10 requests/min for unauthenticated IPs, and a dedicated 20 RAG queries/min limit on all /conversations/* endpoints, preventing expensive vector search and LLM generation from being abused.
Frontend Architecture
The React + TypeScript frontend uses a Feature-Sliced Design pattern, features (chat, documents, auth) are fully self-contained with their own components, hooks, and API modules. All server state is managed with React Query, which handles caching and automatic cache invalidation on mutations. Axios interceptors transparently attach JWT Bearer tokens to every request and handle 401 responses by triggering automatic token refresh, the user never sees a session expiry. The AI streaming chat interface is implemented using the browser's native EventSource API, consuming the Spring AI Server-Sent Events stream to produce the typewriter effect in real time.
AWS Infrastructure & Observability
The five-service stack (frontend, backend, PostgreSQL 16 + pgvector, Prometheus, Grafana) runs on an AWS EC2 t3.small instance (2 vCPU, 2 GB RAM), the minimum viable spec for the ONNX embedding model, which requires ~400 MB of JVM memory at startup. AWS Security Groups expose only port 80 publicly; ports 8080 (backend), 5432 (database), 3000 (Grafana), and 9090 (Prometheus) are restricted to my IP or kept internal to the Docker bridge network. Nginx is configured with proxy_buffering off, a critical non-default directive that prevents the SSE stream from being held in memory before forwarding to the browser. Micrometer instruments the JVM and HTTP layer; Prometheus scrapes /actuator/prometheus every 15 seconds; custom Grafana dashboards surface p95/p99 latency, heap usage, HikariCP pool utilization, and per-endpoint request rates.
Known Trade-Offs & Engineering Maturity
Document processing is currently synchronous, very large PDFs may approach API timeout limits. A production v2 would use Spring's @Async or a message queue for long-running uploads. The ONNX embedding vector is stored as a text type and cast at query time rather than using pgvector's native column type, which adds marginal query overhead. Conversation history is cleaned up daily via a scheduled job, which keeps the database lean but may surprise users who return after 24 hours. These are documented, understood constraints, not unknown risks.